import json
import pandas as pd
with open("1.json", "r", encoding="utf-8") as f:
data = json.load(f)
result = []
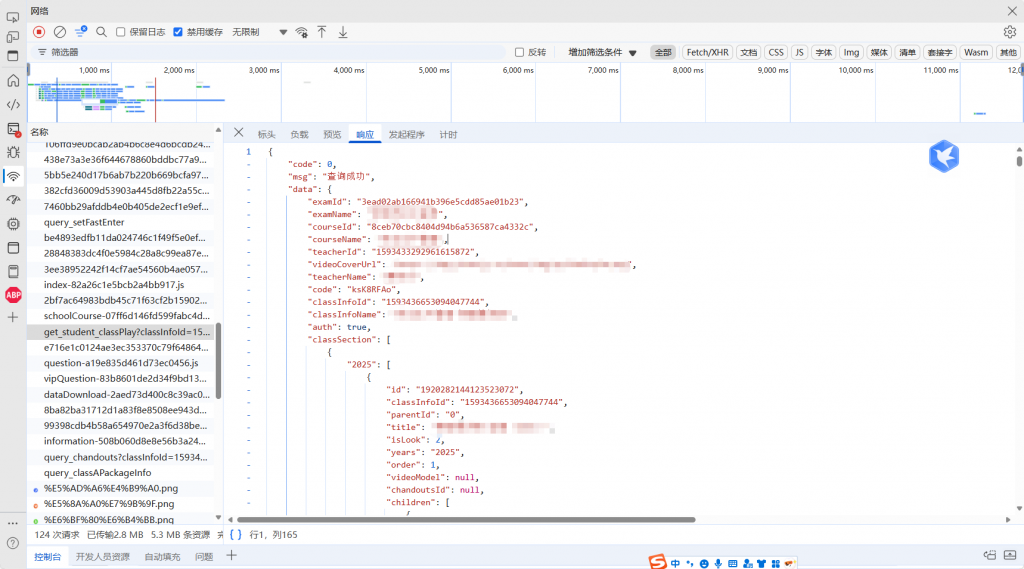
class_sections = data["data"]["classSection"]
for section in class_sections:
for year, chapters in section.items():
for chapter in chapters:
children = chapter.get("children", [])
if children:
for child in children:
title = child.get("title", "")
video = child.get("videoModel")
if video:
url = video.get("vGUrl") or video.get("vBUrl") or video.get("vCUrl")
if url:
result.append({"标题": title, "链接": url})
df = pd.DataFrame(result)
df.to_excel("2.xlsx", index=False)
import os
import requests
from tqdm import tqdm
import pandas as pd
SAVE_DIR = "videos"
os.makedirs(SAVE_DIR, exist_ok=True)
# 读取 Excel 文件
df = pd.read_excel("1.xlsx")
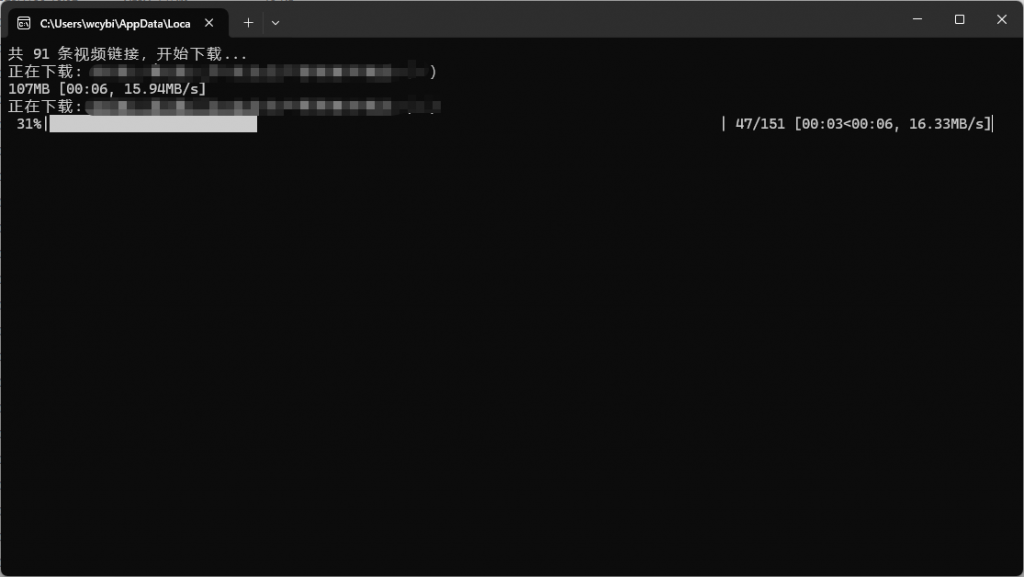
print(f"共 {len(df)} 条视频链接,开始下载...")
for idx, row in df.iterrows():
title = str(row["标题"]).replace("/", "-").replace("\\", "-")
url = row["下载链接"]
filename = os.path.join(SAVE_DIR, f"{title}.mp4")
print(f"正在下载: {title}")
try:
with requests.get(url, stream=True) as r:
r.raise_for_status()
total_size = int(r.headers.get('content-length', 0))
with open(filename, 'wb') as f:
for chunk in tqdm(r.iter_content(1024 * 1024), total=total_size // (1024 * 1024), unit='MB'):
if chunk:
f.write(chunk)
except Exception as e:
print(f"下载失败: {title},错误: {e}")
print("下载完成")