
在开发 PHA-X过程中,我采用SQLlite在本地存储和分析大量节点数据,每个节点对应大量表格和条目。为了保证软件响应速度,结合实际情况,测试在多用户处理大量表的读写性能。
不同数量的表(1000、10000、100000)对 SQLite 进行单/多线程读写混合负载性能测试
在 PRAGMA journal_mode=WAL 和 PRAGMA synchronous=NORMAL 配置下的实际表现。
测试配置如下
| 操作系统 | Windows 11 x64 |
| Python 版本 | 3.12 |
| CPU | 12600kf |
| 内存 | 64 GB DDR4 |
| 磁盘 | SSD |
控制变量,每张表包含 20 列(TEXT类型),每列随机填充字符串100行
一、多线程随机10行数据读写测试
并发线程数:8 个线程。
线程操作:
- 每个线程执行 100 次随机操作。
- 操作类型为随机读或写10行(比例约为 50%/50%)。
- 读操作:
SELECT * FROM table_X LIMIT 10 - 写操作:
INSERT INTO table_X (...) VALUES (...)
分别测试在1000/10000/100000张表下读写的性能情况
| 表数量 | 总耗时 (s) | 操作数 | 平均延迟(ms) | 冷启动时间(ms) | 理论QPS(ops/s) |
| 1000 | 0.78 | 800 | 4.350 | 673.846 | 1022.33 |
| 10000 | 1.95 | 800 | 15.807 | 1814.964 | 410.64 |
| 100000 | 29.71 | 800 | 245.897 | 24747.929 | 26.93 |
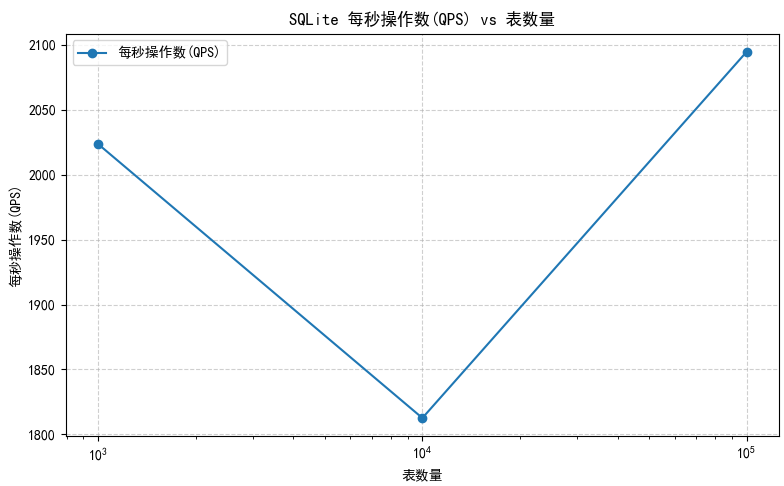
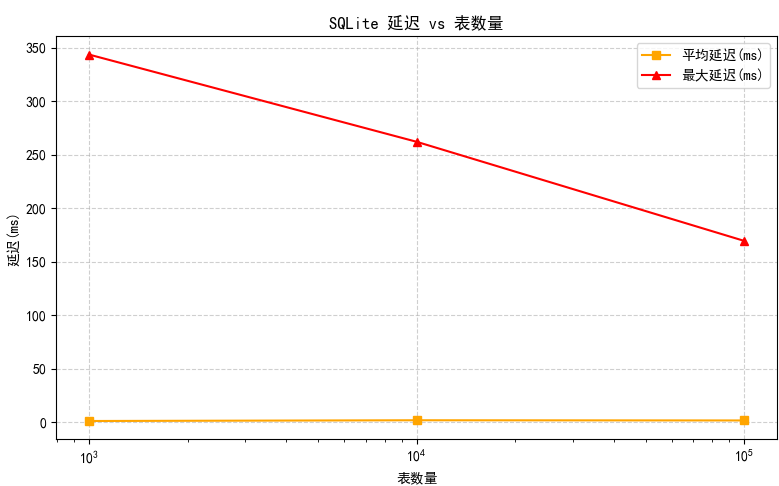
小结:表数量在随机一张表的读/写 10 条数据,不会显著影响单次操作延迟,仅会影响冷启动速度。
二、单线程随机全表数据读写测试
操作说明
- 分别进行1000次读、1000次写数据
- 读操作:对随机选择的 20 张表执行
SELECT * FROM table_X - 写操作:对随机选择的 20 张表删除100行数据并插入100行随机数据
INSERT INTO {tname} ({', '.join(f'col{j}' for j in range(NUM_COLUMNS))}) VALUES ({payload})
分别测试在1000/10000/100000张表下读写的性能情况
| 表数量 | 操作类型 | 操作数 | 平均延迟(ms) | 最大延迟(ms) | 理论QPS(ops/s) |
| 1000 | 读 | 1000 | 1.199 | 8.827 | 834.028 |
| 写 | 1000 | 134.495 | 330.077 | 7.4352 | |
| 10000 | 读 | 1000 | 1.669 | 90.093 | 599.1611 |
| 写 | 1000 | 123.141 | 284.478 | 8.12077 | |
| 100000 | 读 | 1000 | 6.738 | 6.738 | 355.60 |
| 写 | 1000 | 123.439 | 4886.380 | 6.87 |
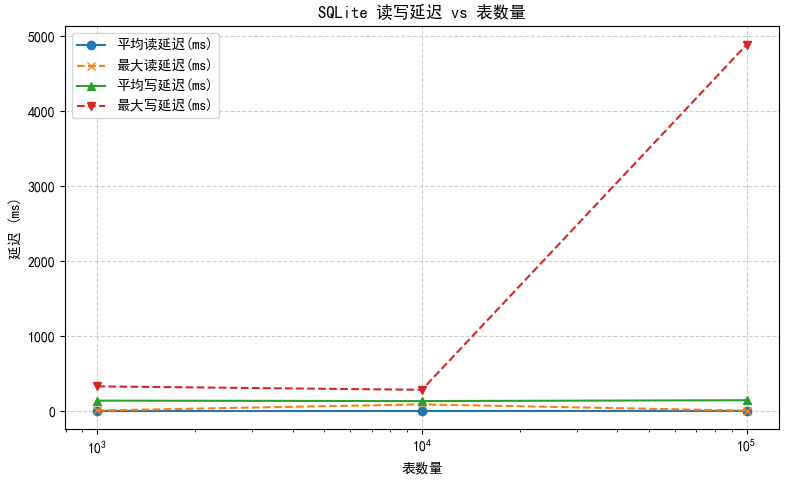
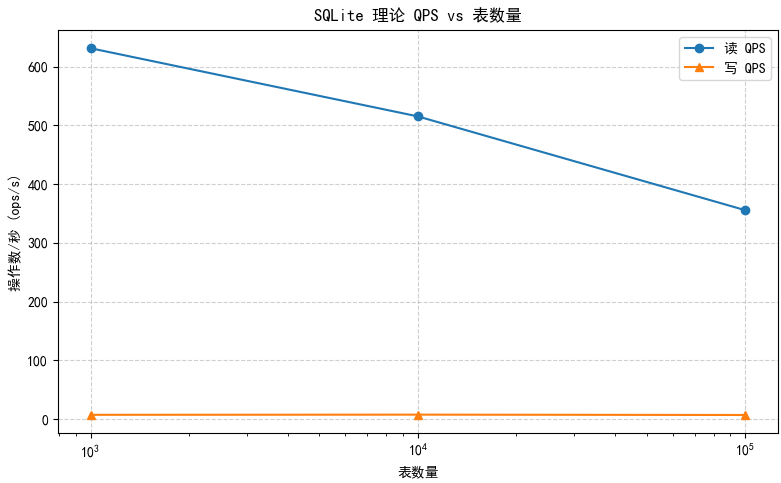
小结:读操作随表数量上升,平均延迟上升较明显,单线程全表扫描性能下降明显,写入操作平均延迟波动不大,考虑磁盘I/O影响,与表数量可能无关。值得注意的是,最大写延迟达到了4886.380ms,多次测试后极少出现,考虑可能受 SQLite 文件 I/O 或操作系统缓存、锁等待等因素影响。